Allocating network resources efficiently and reliably over a long period
Bitesize summary
Paper: Safeguard Network Slicing in 5G: A Learning Augmented Optimization Approach (2020)
key themes: network slicing, predicting and adapting to demand in a constantly changing system, reinforcement learning, deep learning, system safeguarding.
Problem: Optimising resource allocation across a complex 5G system AND ensuring this method is “safe” (i.e. works over a long period) is difficult. Many proposed solutions so far do not tend to work over a long period after initialising, and would need to be reconfigured periodically, which is costly and time-consuming.
Proposed solution: use both combinatorial optimisation techniques and deep reinforcement learning to work out how to allocate resources efficiently, whilst having to do only minimal changes to this approach in future.
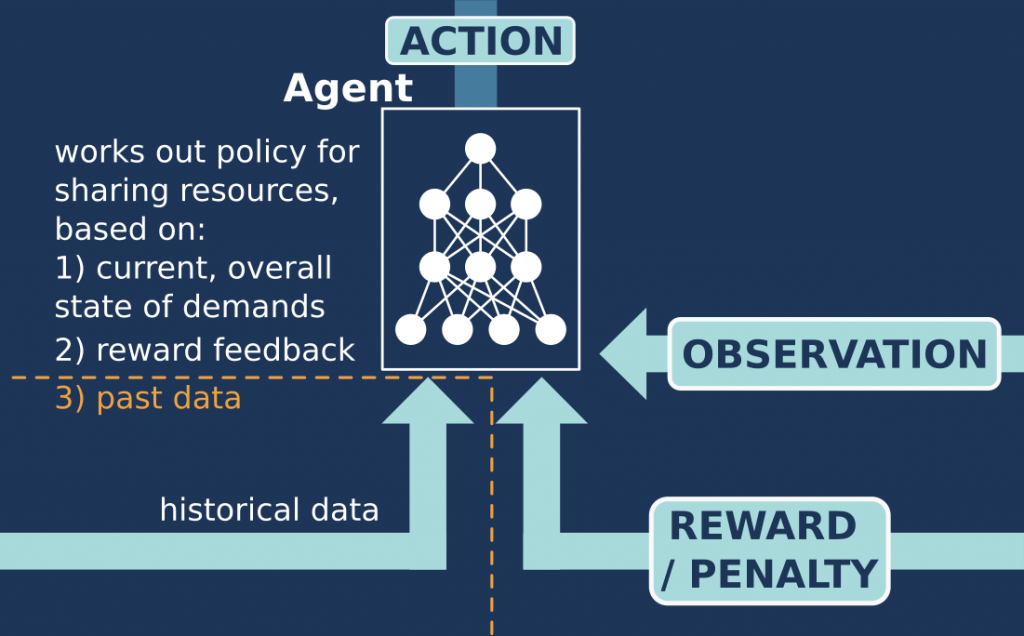
More details
This paper uses a combination of the approaches from the 2018 paper and 2019 paper that were described separately. In this work, the research team design a two-step stochastic program – remember from the 2018 paper that a stochastic method is a mathematical technique for modelling random data. The program they create involves solving a complicated initial problem and then only needing to solve a simple ongoing problem, to decide an optimal method for how resources are allocated. This is great because it reduces the ongoing effort of computing a new approach each time. The problem they are solving is the resource allocation problem: what does each slice need right now? What will it likely need in future? How can the set of resources be shared out most effectively? The end result is a resource allocation policy (“share out the resources in this way”), which is then carried out by a resource scheduling program.
The stochastic program described above is improved by using deep learning, to learn from historical records to help make better future decisions. This is similar to the approach in the 2019 paper, since the method of deep learning is used to find patterns in the data, but there are some differences. In this paper, deep learning is used to review historical records and ‘runtime data’ (current resource requests), rather than just runtime data. This basically adds a huge amount of extra data for the deep learning agent to learn about, that can help it to make predictions about what resources might be needed in future. It still needs to take in and learn from runtime data because you cannot simply predict the future of a really complex system like this, from looking at the historical data once (or even repeatedly, if you could process that much data each time). As described in the 2018 paper summary, this is one of the main reasons for using machine learning in the first place.
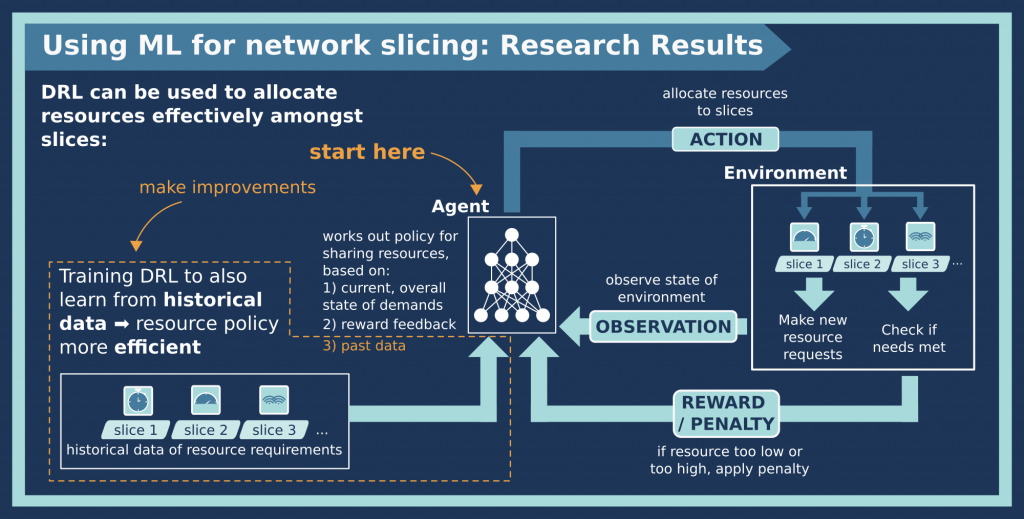
The overall purpose of combining these two approaches – the stochastic method with deep learning – is to improve the “safety” of the system performance. In network design language, the safety of the system performance relates to how reliable the method is over a long time period. In other words: can it make good decisions for a long period, or does it only work for a short time when the state of the system hasn’t changed much from the original system.
You might wonder why the algorithm to allocate resources doesn’t just work – why do we have to be concerned about the long-term reliability of the resource allocation method? We saw in the 2019 paper summary that the machine learning agent is really good at learning as it goes along, but it still needs to keep repeating the process of changing the resource allocations to each slice – more to this slice, less to that one, and so on. That’s because the system changes are really, really difficult to predict, even if you have an AI working it out for you. The method proposed in this work cannot completely avoid this repetitive process, but it can make even better decisions, so that you need to repeat the process less often. This will save a huge amount of computational time and energy.
Why, then, is the system so difficult to predict? A good analogy for this whole process is weather forecasting: there’s a hugely complex set of historical data (temperatures, wind speeds, humidity,…) and there is a hugely complex set of ‘live’ data: current values of temperature, wind speed, humidity,… from the many weather stations around the globe. If you are able to process the historical data, and can make a good model for how these variables (temperature, wind speed,…) change in time, then you can take the live data, put it into the model, and predict the next values of these variables at each location at the next step in time. The problem is the uncertainty or ‘margin of error’ of each of those values; you cannot say exactly that the temperature will change to this value, or wind speed to that value, or so on. You could predict that the temperature might change from 10°C to 12°C in 1 hour, but you would have to add in a range of uncertainty, so perhaps it could be between 11°C and 13°C (in fact, it could be completely wrong, but let’s ignore that for now). So imagine we have a predicted value, and a range of uncertainties, for each location for the next time step, say an hour later than your live values. What happens if you try to predict the next step from this uncertain data? Well, your uncertainties would have to get even larger, because your prediction is based on range of data values for each variable, and all these variables are connected (temperature will affect humidity and wind speed, which is affected by other variables). And, it gets worse the further forward in time you try to predict, as you get further away from your accurate data. Spare a thought for people working in weather forecasting, it’s not an easy problem (and this simple example does not do it justice)!
Example of decreasing certainty (increasing uncertainty) in weather forecasting
These images are from the National Oceanic and Atmospheric Administration (NOAA), to show how the predicted path of Hurricane Lorenzo (October 2019) becomes more uncertain with time. The original images are here.
The forecast on the left was made at 8pm on Tuesday October 1st 2019, and the orange circle gives the ‘live’ position of the storm centre at that time. If you follow the track along (which shows its path over time), you will notice that the spread of the ‘potential track area’ becomes wider, as the forecasters become more uncertain about the position of the storm centre, since it is further away from the current (certain) information at the current time.
Compared to the image on the right, taken the next day (Weds at 11am), the potential track area is not as wide on the Friday, now only 2 days ahead. Notice that the scale on the y axis (showing the lines of latitude from around 40N to 55N) is different in both images, but the width of the track area can be compared to the extent over the UK.
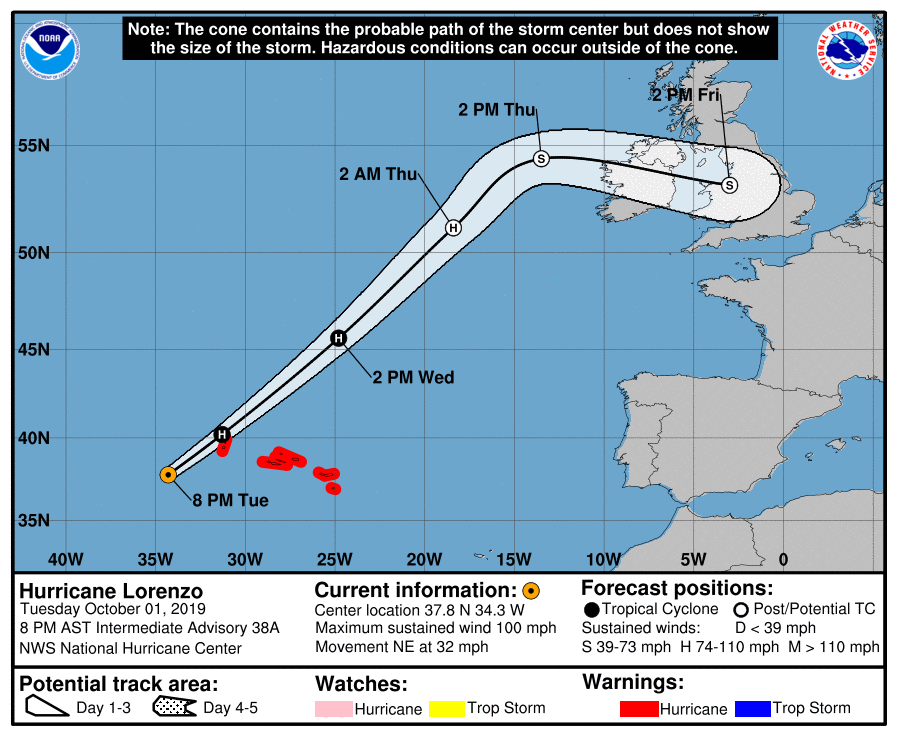
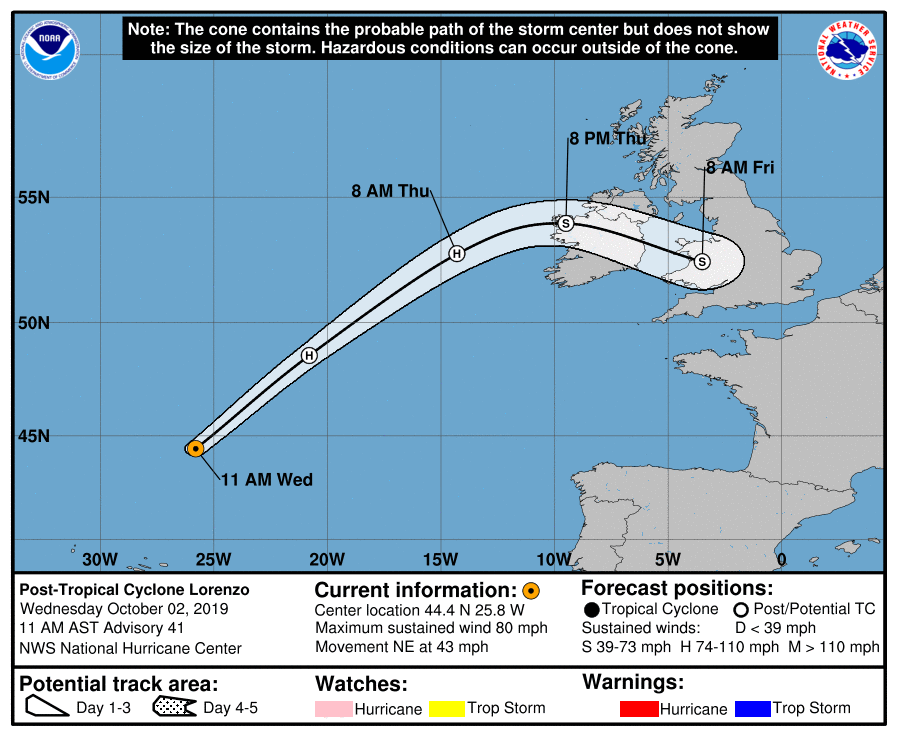
The situation is quite analogous to 5G networks, although with different challenges and complexities. In a 5G network, there is a huge amount of historical data and live data: each person requires a certain value of bandwidth, latency,… equivalent to each location having a value of temperature, wind speed, and so on. And, there is also a great deal of uncertainty for how the system will change – what will each person need in future? As with weather forecasting, each time you try to predict further forwards in time, you need to compound the uncertainties together. By a few steps forward, if you have a large uncertainty each time, the whole thing is so uncertain the data is almost useless (in weather forecasting terms: if you have a range of values for rainfall from 0mm to 200mm, do you really know if and how much it is going to rain?). The challenge is to try to reduce how uncertain your predictions are, so that your predictions last longer, the further away (in time) you try to predict. This is what the research team are trying to achieve for 5G networks by using deep learning and stochastic methods.
This is only the start of the research process for using AI and machine learning techniques with 5G networks. There is still a lot more work to do, to make the resource-scheduling algorithm work even better, and to make it compatible with the really complicated network system. Stay tuned for more paper summaries as the research progresses!