Using deep reinforcement learning to allocate resources in a system of network slices
Bitesize summary
Paper: Data-driven dynamic resource scheduling for network slicing: A Deep reinforcement learning approach (2019)
Key themes: network slicing, predicting and adapting to demand in a constantly changing system, reinforcement learning, deep learning, optimising resource allocation across a big system of VNFs, considering the slicing network as a whole (rather than individual VNFs).
Problem: There is a huge number of potential 5G users, each with different needs and requirements. There are also limited resources to share amongst all these users (e.g. you cannot allocate every user full bandwidth and low latency at all times). Current proposed methods tend to allocate fixed resources to each network “slice”, but this is inefficient.
Proposed solution: Considering the overall system of network slices, use a machine learning technique known as ‘deep reinforcement learning’ to allocate network resources to different network slices most effectively.
More details
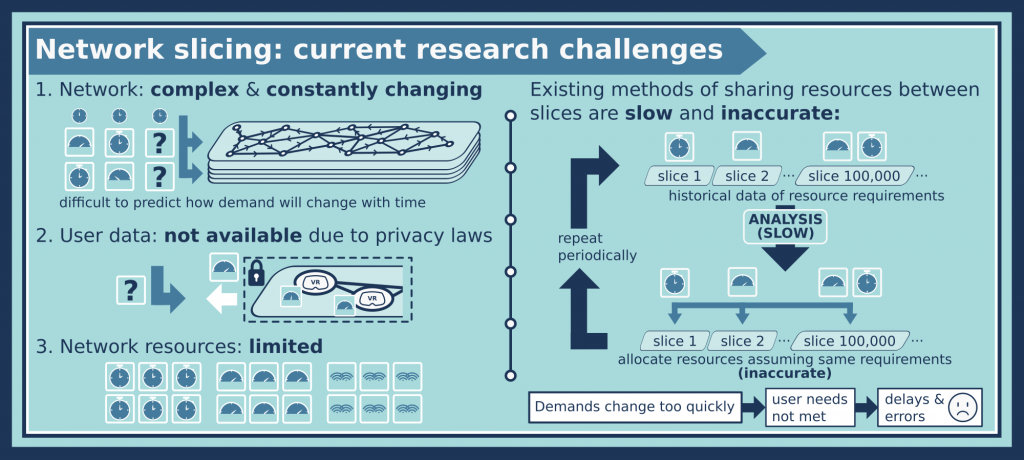
Most research into network slicing so far has looked at allocating a fixed resource (speed or bandwidth for example) to each slice in the network, based on the historical demand. The problem with this approach is that the resources are limited; you might be providing more resources than are actually needed to different slices. It would be much better to allocate resources based on actual requirements!
This sounds like there should be a simple solution: just find out, at each point in time, what resources every user needs, and allocate the resources appropriately. However, there would be a time delay between finding out the resources and allocating them, and this would take a massive amount of computational effort to process all that data afresh in real time. In addition, this would raise major privacy issues – you cannot actually be informed of everyone’s user requirements due to privacy laws. So there are three big problems that make network slicing challenging, that traditional approaches cannot deal with: 1) The network is dynamic (constantly changing) and complex. 2) The user data is not available to help inform how you share out resources. 3) Resources are limited, so they must be shared out effectively.
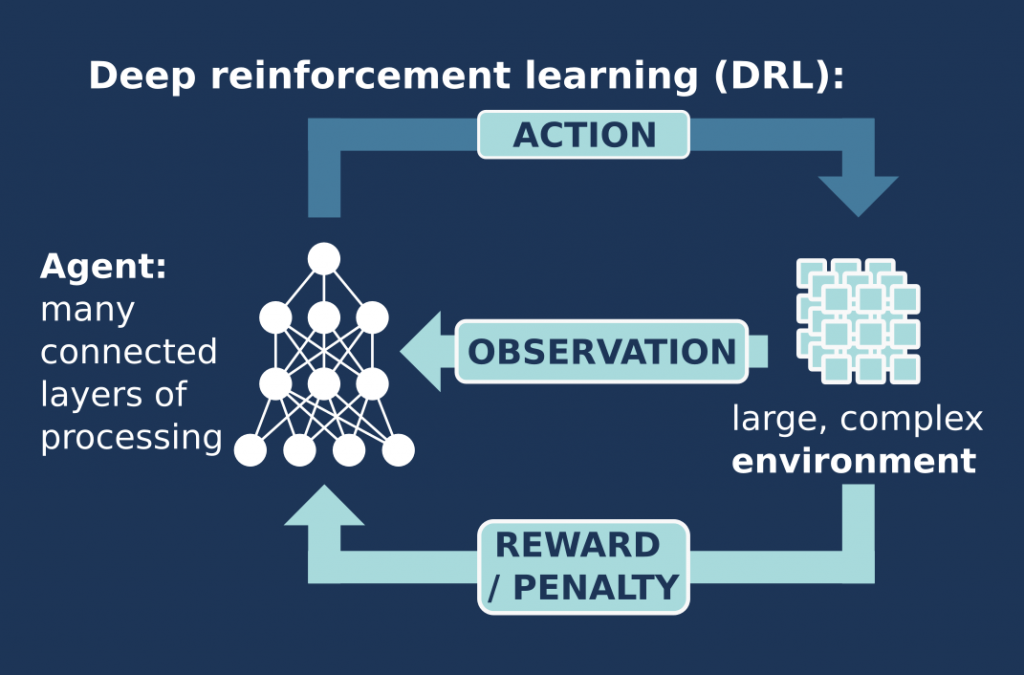
This is where machine learning comes in (see box). By using a machine learning agent instead of a pre-programmed algorithm, the allocation of resources should get better and better, as the agent learns from experience and tries to improve.
What is machine learning?
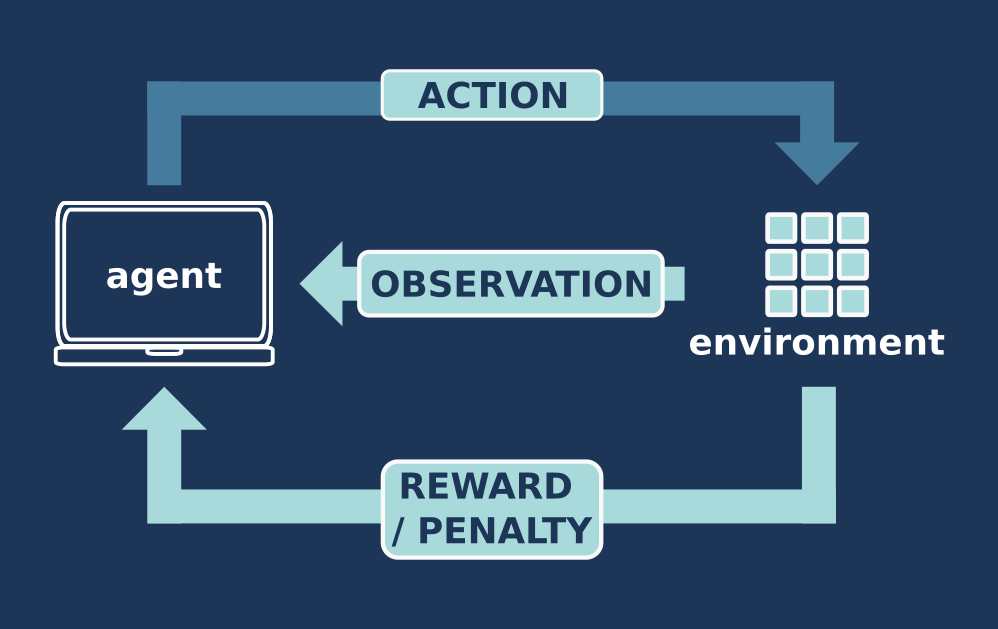
Machine learning involves computer algorithms that automatically learn and improve by analysing data. A useful method of machine learning is called reinforcement learning, which involves training via rewards (in the same way a dog learns to fetch a stick). In this process, a machine learning algorithm or ‘agent’ (dog) takes in some form of input (a thrown stick) from an ‘environment’ (the owner). It then tries out a task or ‘action’ on the environment (retrieve the stick), and the environment gives the agent feedback or ‘reward’ (more stick playing or a treat) depending on how well it carried out this task (more points if dog brings the stick back intact and releases it!). In the same way that we aim for a high score in a computer game (or the dog aims for more treats), the agent changes its next action to try to get a higher reward, and this learning cycle continues.
Machine learning is being applied to many areas of problem-solving in society – and it’s easy to see why: it is like having a dedicated member of staff working on a problem 24/7, who can process vast amounts of information (as quick as a computer can), do so much quicker than a human (or team of humans) could, and keep learning and improving because they are motivated by the things you programme them to be.
In this research project, the team have used a process known as deep reinforcement learning (DRL), which is ideal for carrying out complex tasks on complex data. How does the process work? First, the machine learning (or rather DRL) agent receives data from each slice at each time step, requesting a certain amount of network resources. The agent can tweak the resources allocated previously to give more or less, depending on demand. It will then receive feedback from the different network slices, in the form of a ‘reward’, to tell it how well the resources were allocated. This reward is actually just a number, and the DRL agent is programmed to aim for the highest score it can.
What is deep reinforcement learning?
Deep reinforcement learning combines the method of reinforcement learning (described in the earlier box) with deep learning – let us first understand what deep learning is. Deep learning uses neural networks to process especially complex information. It is known as a ‘neural’ network since it is trying to imitate how the brain works, as a collection of many interconnected neurons. It is a ‘deep’ neural network because it uses many layers of processing – there is a nice explanation here for the enthusiastic reader!
By combining deep learning with reinforcement learning (to make ‘deep reinforcement learning’), the agent can process and discover patterns in the very complex data of the environment, and learn how to better carry out certain actions on the complex environment. This is the especially promising branch of machine learning which is needed for self-driving cars and accurate language interpretation, amongst many other applications.
Using deep learning (designed to process and make connections with complex data) and combining it with reinforcement learning (learning from experience), means that a DRL algorithm is ideal for tackling this complex, regularly changing 5G network. It can also get around the privacy issue, that restricts ‘normal’ algorithms from knowing exactly what is needed when. Privacy is still retained for the users of course! The deep learning algorithm is just really good at finding patterns in complex data: it only needs to observe how the network resources for slices as a whole are requested and then used by each slice, and compare it with the reward feedback which scores how well it works. By observing, testing out resource allocation strategies and getting feedback, it can make much better decisions about scheduling resources than standard algorithms, even without the user data.
Remember the DRL agent also has to cope with having a limited amount of resources to go round, so one of its main challenges is trying to learn how to share them out most effectively. However, since it is looking at the data across many slices, it naturally makes connections between them to get better at sharing out resources. By programming the algorithm to get the best overall or ‘cumulative’ reward, it will try to satisfy the requirements of all the slices as a whole, rather than just the first slices it deals with. This ‘globally optimal solution’ means that most of the network slices’ requests have been mostly satisfied, which is a good compromise considering the resources are limited, and it takes time to work out what to give out where. The other option would be that a few slices are 100% satisfied, and the other slices are not at all satisfied – this is clearly worse than, say, every slice being 80% satisfied.
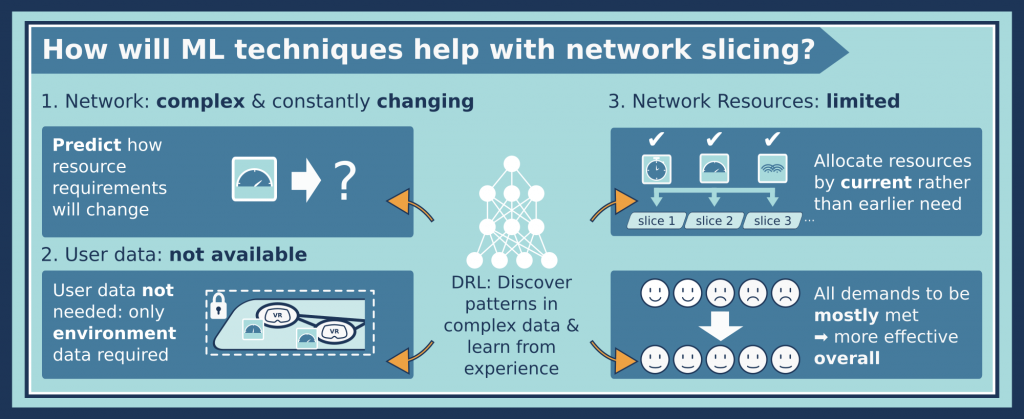
The main result from this work is that the machine learning agent can be trained to be far better than a pre-programmed algorithm at allocating network resources, and it does so as fairly as possible. In the next paper, this work is extended to include the methods of the 2018 paper, to make the DRL agent’s decisions even more long-lasting, so that it does not have to repeat the action-feedback cycle as often.